Complex made simple: the math behind how AI learns
Kristjan Eljand
Business Analyst & Trainer

A simple overview of the mathematical logic used by AI to learn
It is always useful to know how things work. In this article, I will provide a very simple overview of the basic mathematical logic used to train AI models. I promise that if you have a basic education, the following examples will be understandable and you will understand the field of AI a little better.
Creating an AI for sales revenue forecasting
Let’s assume we want to create a new AI model to forecast our company’s sales revenue. We have data from the previous two months on sales revenue, advertising costs, and product prices.

In other words, we want to create a model that shows how our sales revenue depends on our product price and advertising spend. With such a tool, a marketing specialist could, for example, calculate what the sales revenue would be if they spent 50 € on advertising and set the product price at 6 €.
AI is a mathematical formula
At its core, AI is nothing more than a mathematical formula (or a set of formulas). Our sales forecast example could be presented as a mathematical formula like this:

The formula exists, but we do not know what values to assign to the model parameters m and n. In other words, we do not know how much increasing advertising costs or changing the product price affects our sales revenue.
Let's start learning
When we start training the AI, we can give the model parameters random values. For example, let’s first set the advertising cost parameter to 2 and the price parameter to -2.

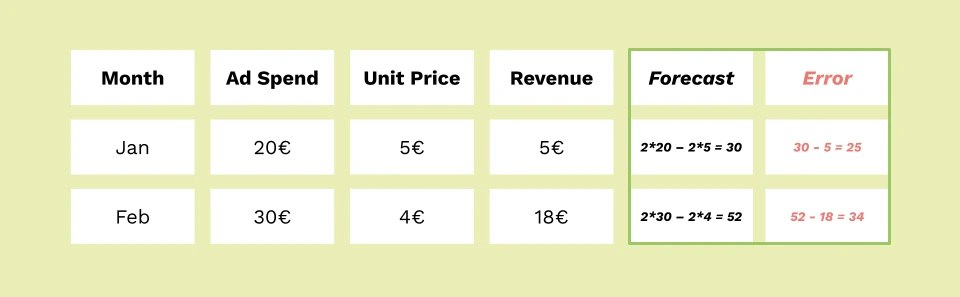
And now we simply test it out. If we multiply the advertising cost and product price by the parameter values, we see that our initial model is too optimistic. In the first month, the actual revenue was 5 €, but our model predicted 30 €. In the second month, the actual revenue was 18 € and our model predicted 52 €.
Let's start learning
The AI learning rule is as follows:
- If the error is 0, the model is perfect;
- If the error is >0, the model gave too optimistic a result, and we should decrease the parameters of positive value variables and increase the parameters of negative value variables;
- If the error is <0, the model was too pessimistic, and we should increase the parameters of positive value variables and decrease the parameters of negative value variables.
Following the learning rule, we must decrease both parameters because both advertising cost and product price are positive value variables in our case. For example, we decrease the advertising cost parameter from 2 to 1 and the price parameter from -2 to -3.

If we calculate again, we see that our model predicts accurately (even very accurately, because the error is 0). Great, our first manually trained AI model is ready.

Testing the model on data not used for training
If it seems to you that the model above is too good to be true, you are right. Our model worked perfectly on the training data. To evaluate the model’s accuracy, it must be tested on data that was not used in the training process.
We trained our model on January and February data. Let’s now check how well the model can predict the sales revenue for March and April.
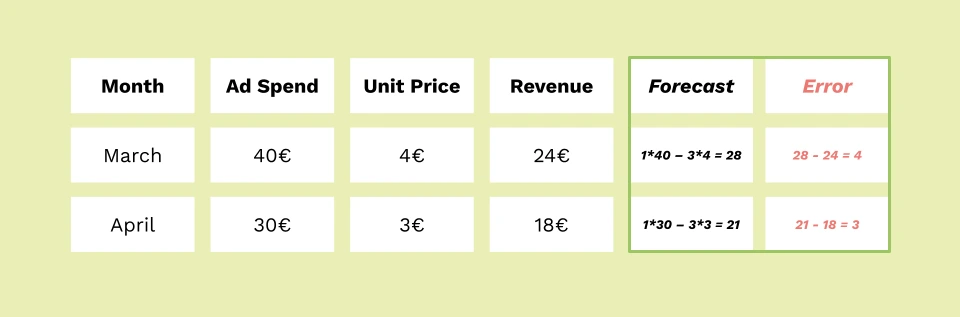
From the table above, we see that the model predicts March sales revenue to be 28 € (actual 24 €) and April revenue to be 21 € (actual 18 €). On average, our model is off by 3.5 euros on new data, and this can be called the accuracy of our model.
Summary
In summary, AI is essentially a mathematical formula. In our example, the formula had 2 parameters; the GPT-4 model has more than a trillion (1 trillion = 1,000,000,000,000) parameters. However, both are trained on the same principle: by gradually changing the model parameters in a direction that reduces the model’s error. It is also important to remember that.
AI learns on training data, but its accuracy can only be assessed on data that has not been used for training (test data).